






















































































Document Domain Randomization for Deep Learning Document Layout Extraction
Description:

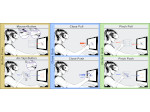
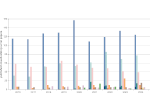
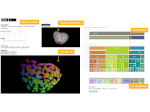
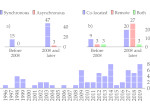
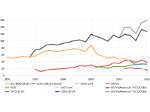
We present document domain randomization (DDR), the first successful transfer of CNNs trained only on graphically rendered pseudo-paper pages to real-world document segmentation. DDR renders pseudo-document pages by modeling randomized textual and non-textual contents of interest, with user-defined layout and font styles to support joint learning of fine-grained classes. We demonstrate competitive results using our DDR approach to extract nine document classes from the benchmark CS-150 and papers published in two domains, namely annual meetings of Association for Computational Linguistics (ACL) and IEEE Visualization (VIS). We compare DDR to conditions of style mismatch, fewer or more noisy samples that are more easily obtained in the real world. We show that high-fidelity semantic information is not necessary to label semantic classes but style mismatch between train and test can lower model accuracy. Using smaller training samples had a slightly detrimental effect. Finally, network models still achieved high test accuracy when correct labels are diluted towards confusing labels; this behavior hold across several classes.
Paper download:  (12.8 MB)
(12.8 MB)

Data: available at DOI 10.21227/326q-bf39
Cross-Reference:
- This work is based on our past work on the VIS30K image dataset.
Paper Reference:
Dataset Reference:
This work was done as in collaboration (primarily) with the Interactive Visual Computing Lab of The Ohio State University, USA, and other research labs.